 About Us
About Us Services
Services Sectors
Sectors Case Studies
Case Studies Blog
Blog Contact
Contact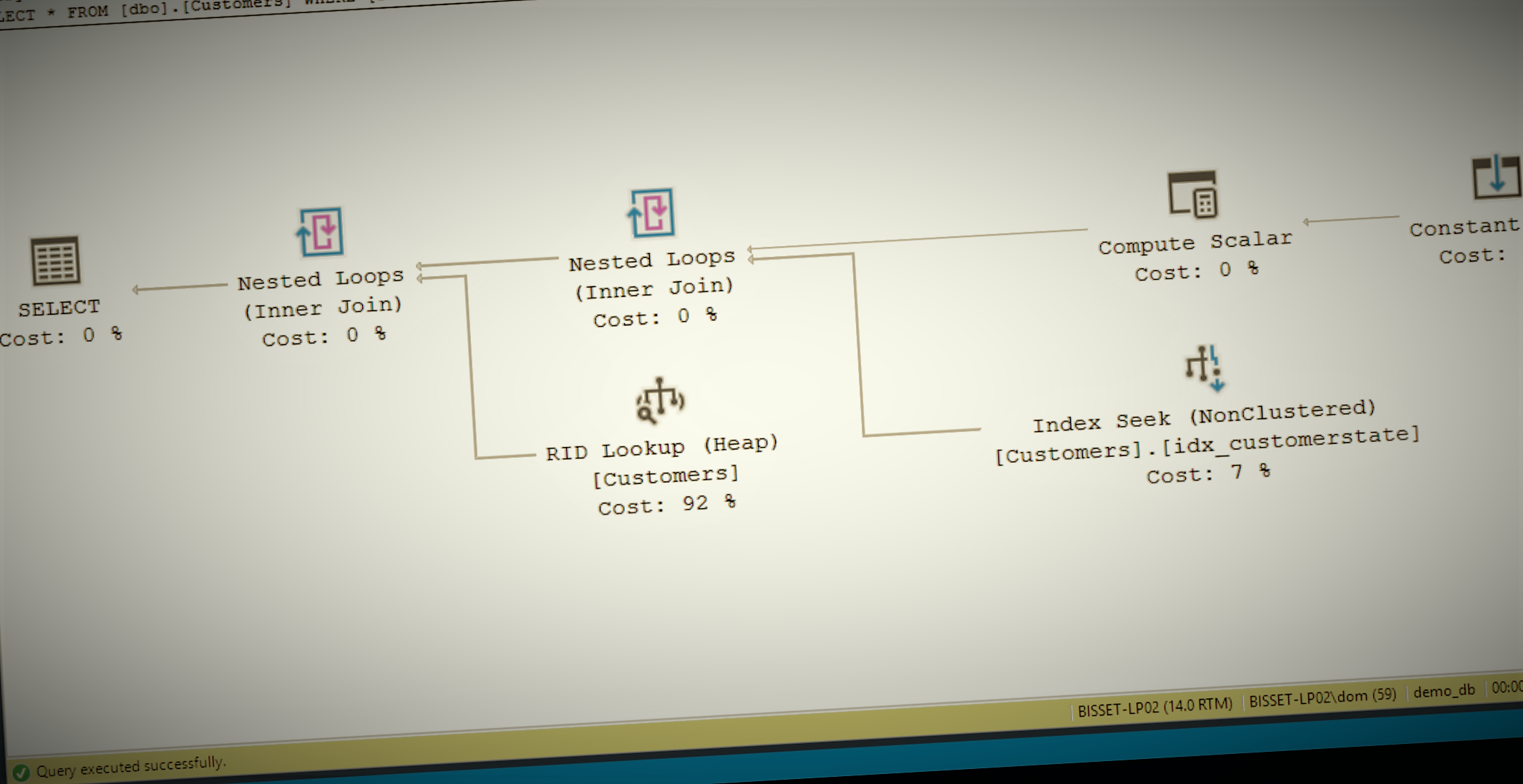
Thoughts from SQLBits
Date: Thursday, February 22, 2018
SQL is a declarative language: you say what you want, and the tool itself decides how to achieve that goal. It’s a programming paradigm that I enjoy. I can focus on the large-scale business problem rather than worrying about the minutiae of accessing the data.
Perhaps I could be accused of having too much faith in this system, of denying the harsh reality that occasionally SQL Server makes bad decisions and of being idealistic when prioritising clear code over optimisation. It it’s been my aim this SQLBits to learn to better harness the tool I use daily
My Wednesday session was all about running High Performance TSQL and was lead by the man who wrote the book on passing Microsofts TSQL exam, Itzik Ben Gan. Here are some of my highlights:

Look out for performance pitfalls
Itzik’s morning session covered in detail the best practice about the cross apply operator. What particularly interested me was the link between table seeks, table scans and the concept of table density when it comes to grouping data.
A high-density column won’t contain many distinct values, so its trivial to find the first of a group by seeking it in the index. The last item can be found by finding the next item and stepping back once. On the other hand, overheads for seeking the data in the index get too great when the density gets too low, so it’s quicker to do a full table scan to find the desired rows.
SQL Server does track column statistics, so should be able to calculate these things, but it can make the wrong choice in even simple statements. Itzik gave a nice series of tips to convince it to use one method or the other to guarantee the desired result.
Another double-underline-worthy moment came when talking about Window Functions: if they are ordered, you need to manually specify the frame to use or it by default chooses a slow option. The SQL Standard states that this is the correct choice because it’s resolves ambiguities, but largely these ambiguities are usually an edge case. It's easy to forget, and something that I've certainly done, but if your frame clause in an ordered window is blank, consider adding ROWS UNBOUNDED PRECEEDING at the end to force the faster behaviour.
Speed improvements are on the horizon
The world is becoming ever-more data obsessed and Microsoft are putting lots of effort into making sure it’s database server can handle the increasing analytical workload. Their focus is centred on Columnstore indices and on processing based on groups of data rather than rows. To hear Itzik talk about it, this new Batch Mode provides remarkable performance improvements when acting on Columnstore Indices.
It turns out you just need a Columnstore index to exist for the query planner to consider using Batch Mode. In fact, since Columnstores are inherently disordered, you’re likely going to use additional B-Tree indices as well, and they’ll be used if the planner deems them more useful. This lead to the following revelation that blew my mind:
This is insane: Enable batch mode processing with a dummy, contradictory columnstore index and suddenly see performance benefits.
— Dominic Bisset (@DominicBisset) 21 February 2018
That's @SQLBits living up to its #magic theme. pic.twitter.com/wi58rBN4np
Even if a Columnstore index isn’t appropriate for your table, you can create a dummy one that is self-contradictory, that will never be used and never slows down inserts, just to turn Batch Mode on.
The good news is that Microsoft is working on opening up this functionality for all indexes in the future. So this One Weird Trick (DBAs hate it!) shouldn’t be necessary for long.
Another up-and-coming speed feature is Adaptive Joins. These are new join operators that get chosen at runtime that will chose between nested loops and hash tables as appropriate. This should reduce slowdowns due to stale statistics or parameter sniffing issues and make database developer lives significantly more straightforward.
Why aren’t you on SQL Server 2016 SP1?
Recently, the server manager for a company we work closely with joked that I was “The only person he’d met that was excited about a server upgrade”. More precisely, I’m excited about SQL Server 2016 Service Pack 1, which opened up all sorts of enterprise-level features for standard-level licence holders. Don’t believe me? Have a look at this table:
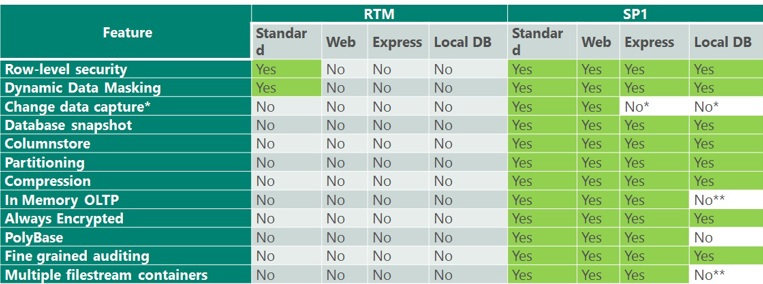
(Source: https://blogs.msdn.microsoft.com/sqlreleaseservices/sql-server-2016-service-pack-1-sp1-released)
There are so many features that get unlocked for non-enterprise users in that service pack, and repeatedly throughout the day we were using them. I’ve already mentioned Columnstore indices – historically you’d have to be an Enterprise user to use them to turn on Batch Mode.
We also talked at length about System Version tables, introduced in 2016, that while not previously an Enterprise feature, take a lot of the load off change tracking. They do away with the need to dig out a dusty backup to run some auditing and make working with Slowly Changing Dimensions a lot more straightforward.
I understand why companies don’t migrate to newer versions, but if apathy is the only thing holding you back, you might want to reconsider.
This is just a small overview of what I’ve picked up from my time here. If this has piqued your interest, keep an eye on this blog, or follow me and Kat on Twitter as we record our experiences.
Posted under: events sqlbits sql SQL Server Performance Databases
Browse all tags- Share:
-


