 About Us
About Us Services
Services Sectors
Sectors Case Studies
Case Studies Blog
Blog Contact
Contact
Thoughts from SQLBits Day 2
Date: Monday, February 26, 2018
SQL is a declarative language: you say what you want, and the tool itself decides how to achieve that goal. It’s a programming paradigm that I enjoy. I can focus on the large-scale business problem rather than worrying about the minutiae of accessing the data.
Perhaps I could be accused of having too much faith in this system, of denying the harsh reality that occasionally SQL Server makes bad decisions and of being idealistic when prioritising clear code over optimisation. It it’s been my aim this SQLBits to learn to better harness the tool I use daily.
Day two found me diving-deep into SQL Server Index analysis, led by Uwe Ricken. I often end up staring at a query plan, seeing something that looked suspect and making a change, only to find it made no different whatsoever. Now I feel a lot more prepared to deal with optimisation issues. Here are some things I learnt:

Don’t fear the Heap
It’s easy to fall into the habit of just throwing a clustered index at every table. You’re going to access the data in the table eventually, so why not structure the data to make that search as fast as possible. It’s so common, when you define the Primary Key on the table it’s automatically used as the basis for a clustered index.
But this isn’t always optimal. It all comes down to the underlying structure of the data on file. Every table is made up of 8KB pages. The first is an Index Allocation Map (IAM) page, which describes where to find the rest of the data. If there is no clustered index defined, the remaining data will be stored on Data pages in the order they were inserted. If there is a clustered index the rows will be inserted into a tree structure, which has one or more tiers of index pages making up the branch nodes of the tree, then data pages in the leaf nodes.
The clustered-table slowdown comes when using non-clustered indices that don’t include the required columns. A non-clustered index is an auxiliary structure, like that of the clustered index with the difference that the leaf nodes just hold references to the data in the main table structure. For a heap, those references are RIDs – codes that point to the specific line within the specific page where the row lives. Once the RID has been retrieved, it’s a single extra read to access the desired row. However, when that main table is a clustered table, that reference is the clustering key, so the clustered index tree must be traversed to pull out the desired information.
This difference means there’s at least one extra read for a clustered index in this situation, and could be several depending on the number of rows in the table and the size in bytes of the row. A few extra reads are inconsequential on their own, but when you’re looking up many rows via the non-clustered index they quickly add up.
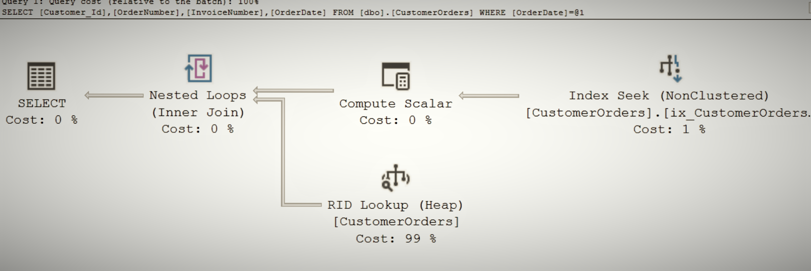
Consider your workloads
You might be tempted to write this off as contrived to prove a point. Uwe drilled a repeated refrain into us throughout the day: consider your workloads.
A good example would be high-frequency inserts: on a clustered table with the identity property assigning keys, you’re going to see huge contention on the final page of the table, as each transaction tries to add rows to that page. Contention causes waits which cause slowdown. Uwe proposed GUIDs as a solution for unique identifiers here (and not the sequential ones which would have the same problem). This is particularly appropriate in cases where data is predominately accessed randomly rather than in an ordered manner.
The simple solution to the clustered-key slowdown is to add the required columns to the non-clustered index as included columns to avoid the need for the key lookup entirely. This could substantially increase data storage requirements, particularly if there are multiple non-clustered indices used regularly. This also requires more work on updates, so this could be off the cards if the data changes frequently.
Alternatively, scrap the clustered index and replace it with a non-clustered version (if it’s needed at all). It’s not ideal if the primary interaction is seeking out individual rows using a primary key, but if the data is usually read en-masse it might be more efficient.
The goal is to minimise reads and writes. If a table has a common usage pattern it can be a good indicator about how to treat the data.

Test Everything
Rules-of-thumb are a great starting point, but there is no substitute for evidence-based decision making. SQL Server gives us the tools to measure the reads required to access data and it’s often straightforward to try few different solutions and pick the best-performing one.
SET STATISTICS IO, TIME ON. Look at the output and find the logical reads. Find the CPU time. Minimise these numbers. To help with this, Uwe introduced us to Ritchie Rump’s statisticsparser.com to record and track the results over different tests. This will definitely come in handy: too often I find myself re-running a long-running stress test after absent-mindedly clearing the results.
The statistics, coupled with the query plan, tell you exactly what is going on. Even with the theoretically optimal indexing strategy, it’s possible those indexes aren’t used. Perhaps there’s a column that should be included but isn’t. Maybe one of the terms in a join predicate is being manipulated or has a datatype mismatch requiring a CAST such that the planner can’t understand it. These predicates might be hidden and can be seen by adding OPTION (QUERYTRACEON 9130) at the end of the query.
Are there discrepancies between estimated and actual rows? This could indicate outdated statistics or problems with variables or parameters in stored procedures. This means the planner could make different decisions to what’s expected. It can also result in incorrect amounts of memory being requested and, if not enough was granted, very slow performance as the system as it spills into tempdb.
I could go on, but I’d just be reiterating the entire talk. If this has piqued your interest, check out my day one blog post or Kat’s recap of her SQLBits 2017 experiences. I’ve also got a final post in the works, so keep an eye out here for my impressions from Friday’s short talks, coming soon.

Posted under: sql SQL Server sqlbits events Performance Databases
Browse all tags- Share:
-


